GLM-4.6 is the latest major release in Z.ai’s (formerly Zhipu AI) GLM family: a 4th-generation, large-language MoE (Mixture-of-Experts) model tuned for agentic workflows, long-context reasoning and real-world coding. The release emphasizes practical agent/tool integration, a very large context window, and open-weight availability for local deployment.
Key features
- Long context — native 200K token context window (expanded from 128K). (docs.z.ai)
- Coding & agentic capability — marketed improvements on real-world coding tasks and better tool invocation for agents.
- Efficiency — reported ~30% lower token consumption vs GLM-4.5 on Z.ai’s tests.
- Deployment & quantization — first announced FP8 and Int4 integration for Cambricon chips; native FP8 support on Moore Threads via vLLM.
- Model size & tensor type — published artifacts indicate a ~357B-parameter model (BF16 / F32 tensors) on Hugging Face.
Technical details
Modalities & formats. GLM-4.6 is a text-only LLM (input and output modalities: text). Context length = 200K tokens; max output = 128K tokens.
Quantization & hardware support. The team reports FP8/Int4 quantization on Cambricon chips and native FP8 execution on Moore Threads GPUs using vLLM for inference — important for lowering inference cost and allowing on-prem and domestic cloud deployments.
Tooling & integrations. GLM-4.6 is distributed through Z.ai’s API, third-party provider networks (e.g., CometAPI), and integrated into coding agents (Claude Code, Cline, Roo Code, Kilo Code).
Technical details
Modalities & formats. GLM-4.6 is a text-only LLM (input and output modalities: text). Context length = 200K tokens; max output = 128K tokens.
Quantization & hardware support. The team reports FP8/Int4 quantization on Cambricon chips and native FP8 execution on Moore Threads GPUs using vLLM for inference — important for lowering inference cost and allowing on-prem and domestic cloud deployments.
Tooling & integrations. GLM-4.6 is distributed through Z.ai’s API, third-party provider networks (e.g., CometAPI), and integrated into coding agents (Claude Code, Cline, Roo Code, Kilo Code).
Benchmark performance
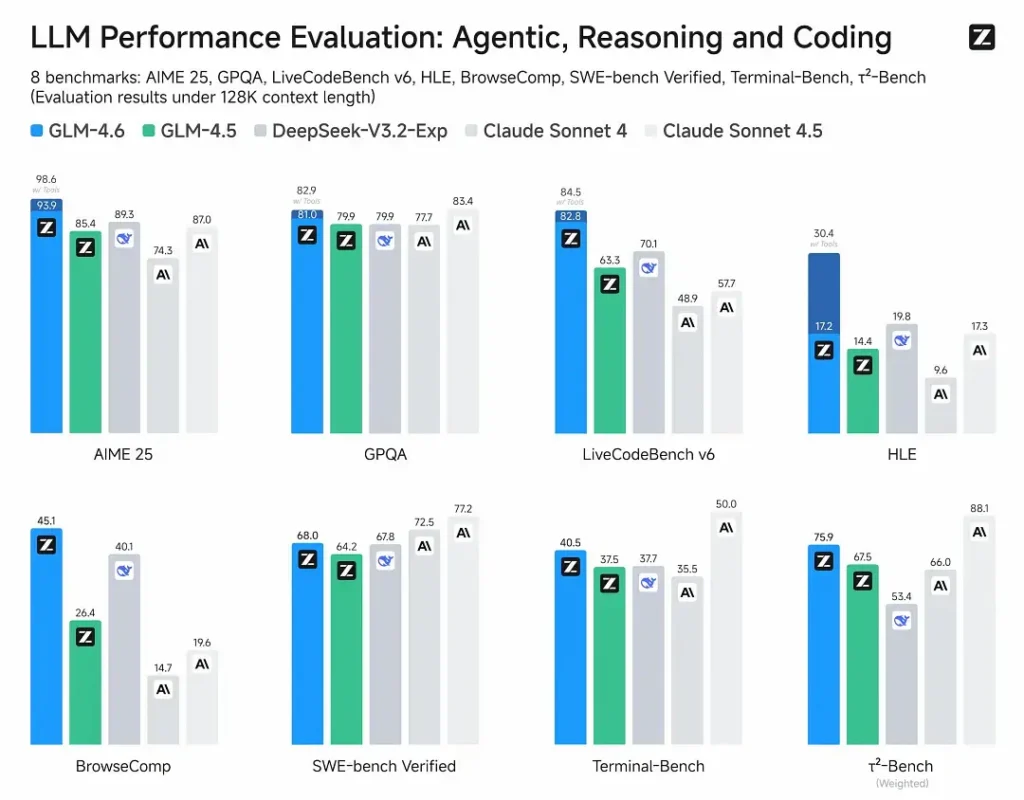
- Published evaluations: GLM-4.6 was tested on eight public benchmarks covering agents, reasoning and coding and shows clear gains over GLM-4.5. On human-evaluated, real-world coding tests (extended CC-Bench), GLM-4.6 uses ~15% fewer tokens vs GLM-4.5 and posts a ~48.6% win rate vs Anthropic’s Claude Sonnet 4 (near-parity on many leaderboards).
- Positioning: results claim GLM-4.6 is competitive with leading domestic and international models (examples cited include DeepSeek-V3.1 and Claude Sonnet 4).
Limitations & risks
- Hallucinations & mistakes: like all current LLMs, GLM-4.6 can and does make factual errors — Z.ai’s docs explicitly warn outputs may contain mistakes. Users should apply verification & retrieval/RAG for critical content.
- Model complexity & serving cost: 200K context and very large outputs dramatically increase memory & latency demands and can raise inference costs; quantized/inference engineering is required to run at scale.
- Domain gaps: while GLM-4.6 reports strong agent/coding performance, some public reports note it still lags certain versions of competing models in specific microbenchmarks (e.g., some coding metrics vs Sonnet 4.5). Assess per-task before replacing production models.
- Safety & policy: open weights increase accessibility but also raise stewardship questions (mitigations, guardrails, and red-teaming remain the user’s responsibility).
Use cases
- Agentic systems & tool orchestration: long agent traces, multi-tool planning, dynamic tool invocation; the model’s agentic tuning is a key selling point.
- Real-world coding assistants: multi-turn code generation, code review and interactive IDE assistants (integrated in Claude Code, Cline, Roo Code—per Z.ai). Token efficiency improvements make it attractive for heavy-use developer plans.
- Long-document workflows: summarization, multi-document synthesis, long legal/technical reviews due to the 200K window.
- Content creation & virtual characters: extended dialogues, consistent persona maintenance in multi-turn scenarios.
How GLM-4.6 compares to other models
- GLM-4.5 → GLM-4.6: step change in context size (128K → 200K) and token efficiency (~15% fewer tokens on CC-Bench); improved agent/tool use.
- GLM-4.6 vs Claude Sonnet 4 / Sonnet 4.5: Z.ai reports near parity on several leaderboards and a ~48.6% win rate on the CC-Bench real-world coding tasks (i.e., close competition, with some microbenchmarks where Sonnet still leads). For many engineering teams, GLM-4.6 is positioned as a cost-efficient alternative.
- GLM-4.6 vs other long-context models (DeepSeek, Gemini variants, GPT-4 family): GLM-4.6 emphasizes large context & agentic coding workflows; relative strengths depend on metric (token efficiency/agent integration vs raw code synthesis accuracy or safety pipelines). Empirical selection should be task-driven.
Zhipu AI’s latest flagship model GLM-4.6 released: 355B total params, 32B active. Surpasses GLM-4.5 in all core capabilities.
- Coding: Aligns with Claude Sonnet 4, best in China.
- Context: Expanded to 200K (from 128K).
- Reasoning: Improved, supports tool calling during inference.
- Search: Enhanced tool calling and agent performance.
- Writing: Better aligns with human preferences in style, readability, and role-playing.
- Multilingual: Boosted cross-language translation.